Beyond Serverless: The Infrastructure for Multi-Agent AI
TL;DR
- The problem: multi-agent AI systems require infrastructure that supports persistent state, high-memory, long-running compute, and secure networking. Standard deployment options fall short: serverless platforms (like Vercel) have strict execution timeouts and are stateless, while IaaS platforms (like AWS/GCP) create massive DevOps overhead.
- The pillars of AI infrastructure: production-ready agents are built on three pillars, including Persistent State for memory, Specialized Compute for long-running tasks, and Secure Communication between components.
- The solution: Render provides a unified platform that delivers all three pillars as a native, unified solution. With long-running background workers, integrated Postgres with
pgvector, and zero-config private networking, Render eliminates the complexity of building AI infrastructure. - The takeaway: stop wrestling with infrastructure and focus on building intelligent agents. Render is the fastest way to go from a multi-agent prototype to a scalable, production-ready application.
You’ve built a sophisticated multi-agent system with frameworks like LangChain, LangGraph, or CrewAI. The agents collaborate, reason, and execute complex tasks. The demo is impressive. But then comes the critical question: 'How do we move this to production?'
This is where the exhilarating work of AI development collides with the unforgiving realities of infrastructure. Agentic systems are a demanding new breed of software, fundamentally different from the stateless APIs that legacy cloud platforms were designed to handle. Their requirements for persistent memory, long-running computation, and secure inter-service communication are non-negotiable, yet forcing them onto standard infrastructure creates a dilemma of complexity and compromise.
And it shouldn’t be this way. Deploying them shouldn’t force you to become a full-time DevOps engineer. That’s exactly why this guide explains the infrastructure, breaking down the essential requirements for production-ready AI. It also presents a powerful, unified platform that lets you focus on building intelligent agents, not wrestling with cloud complexity.
The deployment dilemma: stuck between serverless limits and IaaS complexity
The path to production for a multi-agent system is often a frustrating choice between two unsatisfying extremes: the limitations of serverless platforms and the overwhelming complexity of Infrastructure-as-a-Service (IaaS).
The serverless ceiling: why ephemeral functions can't run stateful agents
Platforms like Vercel excel at deploying frontends, but their ephemeral, stateless model is fundamentally misaligned with agentic AI. The core issue is operational: agents require persistent processes that can run for minutes or hours, making them incompatible with the temporary nature of serverless functions.
This incompatibility creates immediate technical barriers. Serverless functions have maximum execution timeouts that are often too short for AI tasks, typically capping out at 15 minutes on standard paid plans. This architecture also lacks support for persistent, long-running processes like WebSockets needed for real-time communication.
These limitations force developers into a complex multi-cloud architecture where the frontend lives on Vercel, but the core AI logic, databases, and task queues are hosted elsewhere. This separation negates the simplicity serverless promises, reintroducing the very infrastructure complexity developers sought to avoid.
The IaaS complexity trap: when you're forced to become a DevOps engineer
When deploying a complex AI application, the default path often leads to a hyperscale cloud like AWS or GCP. Although these platforms are strong enough to handle any workload, this flexibility comes at a steep cost in complexity. Suddenly, your team’s focus shifts from iterating on models to configuring Virtual Private Clouds (VPCs), defining IAM roles, and managing Kubernetes clusters.
The high-level task of "deployment" dissolves into a granular, time-consuming checklist of infrastructure management. Instead of refining agentic workflows, you are forced to become a full-time DevOps engineer. This trade-off slows product velocity for weeks of setup and creates infrastructure sprawl that is difficult to maintain.
Feature | Vercel (serverless) | AWS/GCP (IaaS) | Render (unified platform) |
|---|---|---|---|
Long-running processes | ❌ No (Timeouts up to 15 mins) | ✅ Yes (Requires complex setup) | ✅ Yes (persistent background workers with no timeouts) |
High memory support | ❌ Limited (Up to 4 GB) | ✅ Yes (Requires manual provisioning) | ✅ Yes (High-memory instances available) |
Integrated pgvector | ❌ No (Requires external DB) | ❌ No (Requires manual setup/integration) | ✅ Yes (Built-in pgvector extension) |
Private networking | ❌ Limited (Cross-service is complex) | ✅ Yes (Requires deep VPC/IAM expertise) | ✅ Yes (Zero-config, automatic for all services) |
DevOps overhead | Low | Very High | Very Low |
The path forward requires stepping back from specific platforms and asking a more fundamental question, i.e., what do multi-agent systems actually need? By understanding the core infrastructure requirements first, we can evaluate which platform approach genuinely solves the deployment dilemma rather than simply shifting the burden elsewhere.
What makes multi-agent AI infrastructure so different?
Deploying a sophisticated multi-agent system moves beyond the stateless, request-response world of traditional web applications. Production-ready agents demand a new way of thinking about infrastructure, grounded in three core pillars, including persistent state, specialized compute, and secure, composable communication. Getting these pillars right is the difference between a promising demo and a reliable, scalable AI application.
Each of these pillars addresses a specific technical requirement that distinguishes agentic workloads from traditional web applications.
Pillar 1: persistent state for long-term memory and context
Unlike stateless APIs, AI agents must remember past interactions to maintain context and improve over time. This requires a robust state management strategy, combining relational databases for structured data, key-value stores for caching, and specialized vector databases (like Pinecone or Qdrant) to enable semantic search for Retrieval-Augmented Generation (RAG).
Pillar 2: high-memory, long-running compute for complex tasks
Agentic workloads demand a different type of compute. Executing complex, multi-step tasks requires loading large models and embeddings into memory, processing extensive context windows, and maintaining state across interactions. This necessitates long-running, persistent processes with significant RAM, an architecture designed for tasks that can run for minutes or hours.
Pillar 3: secure communication for composable systems
Modern AI applications are not monolithic. They are distributed systems where specialized components must communicate securely and efficiently. This compositional nature, however, introduces a larger attack surface, making robust communication patterns essential. This communication happens in three distinct patterns:
- Internal communication: core components, like an API server and its database, need secure, direct lines of communication over a private network, completely isolated from the public internet.
- Asynchronous communication: for event-driven workflows, agents require decoupled communication, often using a message broker to pass tasks between services without them being tightly linked.
- External communication: agents must make secure external API calls to third-party services, such as a GPU cloud for model inference or a managed vector database, requiring reliable management of outbound traffic and credentials.
Pillar | Core requirement for AI agents | How Render provides an out-of-the-box solution |
|---|---|---|
Persistent state | Agents need long-term memory to maintain context, track task progress, and recall past interactions. This requires integrated databases, caches, and vector stores. | Render offers managed Postgres with pgvector, Render Key Value, and Persistent Disks, all connected on a private network. |
Specialized compute | Complex agentic logic involves multi-step tasks that can run for minutes or hours and require significant memory to load models and process data. | Render's background workers are persistent processes with no execution timeouts and support high-memory instances, ideal for demanding AI workloads. |
Secure communication | AI systems are composed of multiple services (APIs, databases, workers) that must communicate securely and efficiently, both internally and with external services. | Render provides a zero-config private network for all internal services and supports static outbound IPs for secure connections to third-party APIs. |
Render: the unified platform for agentic AI infrastructure
Deploying a sophisticated AI backend shouldn't require you to become a full-time cloud architect. The ideal platform must natively provide the three pillars of agentic infrastructure: state, compute, and communication, in a powerful way. Render is designed as a unified, all-in-one platform where these components are first-class citizens that work together effectively, eliminating the complex "glue code" and configuration nightmare of traditional Infrastructure-as-a-Service (IaaS).
Solving for state: from integrated pgvector to persistent disks
State provides the memory and context needed for complex tasks, and Render addresses this with integrated, first-class services. The journey begins with Render Postgres, which includes built-in support for the pgvector extension, letting you use your primary database as a powerful vector store. For caching and brokering tasks between agents, Render Key Value, a fully managed, Redis®-compatible service, provides a high-speed layer for ephemeral data.
Finally, Persistent Disks offer maximum flexibility for stateful workloads. This feature provides a robust option for specialized use cases, allowing you to self-host vector databases like Chroma or store large model artifacts directly on the platform. This is a capability unavailable on most serverless alternatives.
Render service | Primary use case for AI agents | Key benefit |
|---|---|---|
Render Postgres with pgvector | Long-term memory, RAG implementations, and structured data storage. | A powerful vector database co-located with your application, eliminating network latency and simplifying your stack. |
Render Key Value | Caching, session management, and as a high-speed message broker (e.g., for Celery) between agents. | Decouples services for resilient, asynchronous workflows with a fully managed, high-performance solution. |
Persistent Disks | Storing large files/models, or self-hosting specialized databases like Chroma or Weaviate. | Provides block storage that persists across deploys, offering maximum flexibility for stateful workloads. |
Solving for compute: persistent workers with scalable high memory
Render's core philosophy is "serverful," providing the persistent, long-running compute that agentic workloads demand. Unlike traditional serverless functions that are ephemeral, Render’s web services and background workers are designed for continuous operation. This model is essential for AI agents that must load large models, process complex data, and execute multi-step tasks that can run for hours, not seconds.
To handle these jobs, you can select instance plans with significant memory required to host demanding agents. Critically, Render's architecture distinguishes between request types. Although web services handle synchronous HTTP requests, background workers are persistent processes with no execution time limit**,** making them the ideal environment for core agent logic.
Furthermore, first-class native Docker support provides complete environmental control. You can deploy any custom AI framework, ensuring your application runs on Render regardless of its system-level dependencies.
Solving for communication: zero-config private networking and secure egress
Modern AI systems are composed of multiple, specialized components that must communicate securely. Render simplifies this with two key features, i.e., a zero-configuration private network for internal traffic and a clear solution for secure external communication.
A key feature is the private network, which creates a secure, internal environment for your services automatically. A web service, background worker, Postgres database, and Render Key Value can all communicate using simple, stable internal hostnames right out of the box. This eliminates the complex and error-prone process of configuring VPCs, subnets, and network ACLs, which is a significant barrier on traditional cloud platforms.
For external API calls to services like GPU providers or managed vector databases, securing outbound traffic is critical. Many third-party APIs enhance security by requiring connections from a whitelisted static IP address. While Render services send traffic from a shared range of IPs, you can achieve a static outbound IP by using an integrated add-on like QuotaGuard. This routes your application's outbound requests through a static IP, allowing you to securely connect to IP-restricted services without sacrificing the platform's ease of use.
These capabilities, such as persistent state, long-running compute, and secure networking, are powerful in isolation, but their real value emerges when combined into a complete system. Let's examine a concrete reference architecture that brings together all three pillars, illustrating how a production multi-agent application would be structured on Render from the API layer down to the database.
The blueprint: a reference architecture for a multi-agent system on Render
Moving from theory to practice, this reference architecture provides a tangible blueprint for deploying a sophisticated, multi-agent system on Render. This pattern illustrates how to combine Render's managed services into a secure, scalable, and powerful AI application, ensuring the components work well together from day one. This entire architecture can be defined in a single render.yaml file, allowing you to version-control your infrastructure and spin up identical environments for testing or staging in minutes.
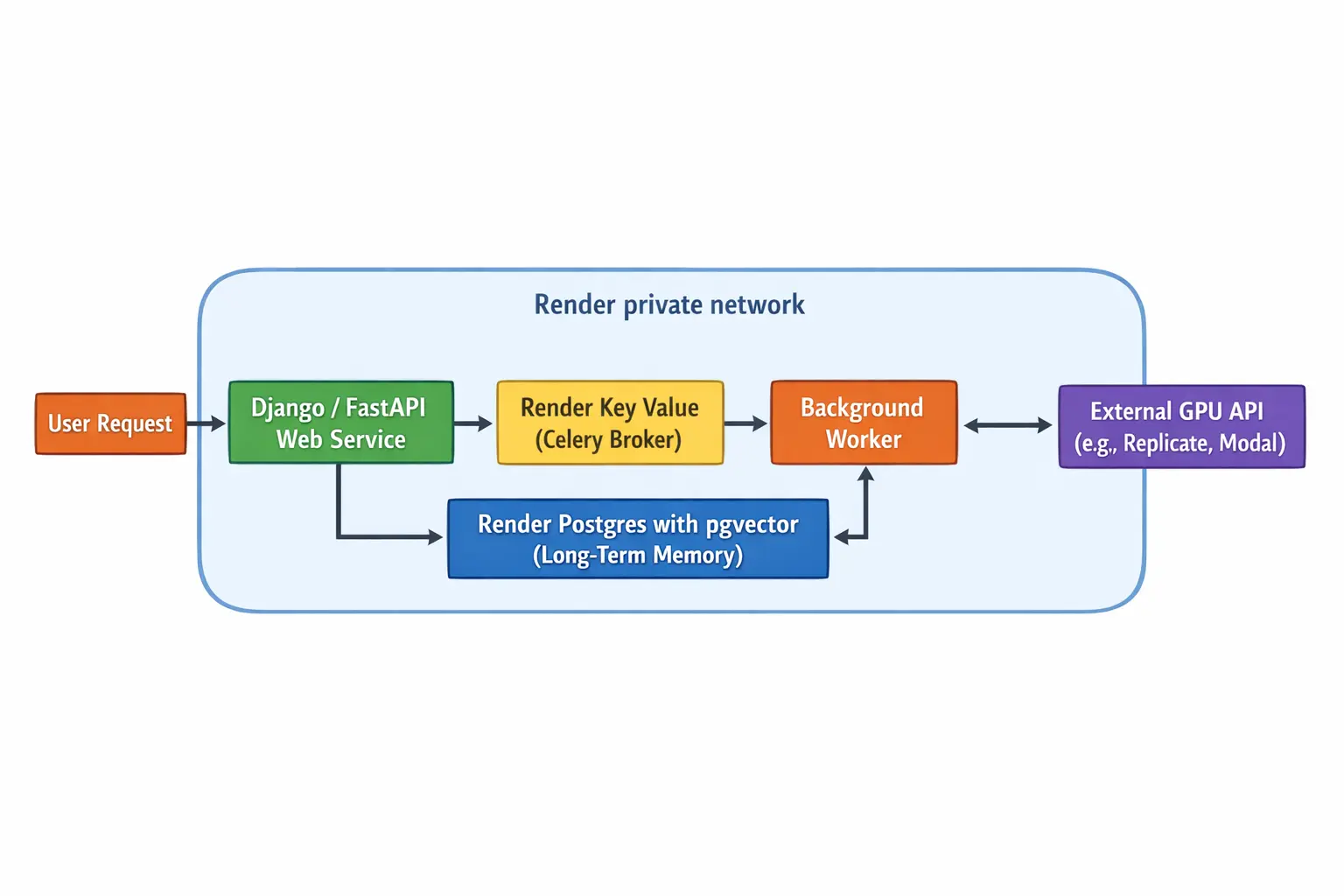
The API entrypoint: a lightweight web service
This is the public-facing entry point of the application. It receives inbound API requests and is responsible for dispatching tasks to the background workers. By handling only the initial, lightweight request, it remains fast and responsive, offloading all heavy computation.
The AI core: a high-memory background worker
Operating on a high-memory instance, the background worker is the core of the AI logic. As a long-running, persistent process (e.g., a Celery worker), it's perfectly suited for executing the agent's complex, multi-step tasks, loading large models into memory, and performing computations that can run for minutes or even hours without timing out.
The memory layer: Postgres with pgvector
This managed database serves as the agent's long-term memory. With the powerful pgvector extension enabled, it facilitates sophisticated semantic search and retrieval-augmented generation (RAG) capabilities. This provides an ideal foundation for applications built with frameworks like Django to integrate powerful vector search capabilities.
The communication hub: Task broker
Render Key Value acts as the message broker between the web service and the background workers. When a new task comes in, the web service places it on this queue, and a background worker picks it up for execution. This decouples the components, ensuring that the system is resilient and can handle asynchronous workflows efficiently.
The secure foundation: the Render private network
All internal components: the web service, background worker, Postgres database, and Render Key Value, are automatically connected on a Render private network. This zero-configuration network ensures that all inter-service communication is secure and isolated from the public internet, eliminating the need to manually configure VPCs, subnets, or firewall rules.
Component role | Recommended implementation | Corresponding Render service |
|---|---|---|
API entrypoint | Lightweight API server (e.g., Django, FastAPI) to receive requests and dispatch tasks. | Web service |
Core AI logic | Long-running process for multi-step tasks, model loading, and intensive computation. | Background worker |
Task queue/broker | Decouples the API from the AI logic for asynchronous processing. | Render Key Value |
Long-term memory / RAG | Stores conversation history and enables semantic search for context retrieval. | Render Postgres with pgvector |
Internal communication | Secure, low-latency networking between all internal application components. | Render private network (automatic) |
Conclusion: focus on your agents, not your infrastructure
Deploying stateful, multi-agent AI systems creates an infrastructure dilemma. Serverless platforms lack the required persistence and compute duration, although IaaS forces ML teams into the role of full-time cloud architects, slowing innovation.
Render solves this by providing a unified platform where production-ready AI infrastructure works out of the box. Persistent background workers run complex tasks for hours, not minutes. Integrated databases with pgvector manage long-term memory. All components communicate securely over a zero-config private network.
This technical simplicity is paired with predictable pricing, allowing you to scale without the volatile cloud bills common on usage-based platforms. Render also accelerates the development lifecycle with features like Preview Environments, which automatically deploy a full-stack preview of your agent for every pull request.
This allows you to stop wrestling with YAML files and cloud networking and instead focus on what creates unique value: building better AI products.
Ready to deploy your AI agent without the DevOps overhead?