AI development sometimes feels like a throwback to the pioneer era: paths are unmarked, maps are scarce, and the ground shifts under your feet as you're trying to make progress. OpenAI's Apps SDK is one of the latest additions to this frontier: conversation becomes the UI, and tools turn intent into actions. Will it be gold or gravel? There's only one way to find out.
I spent a couple of days building a movie recommendation app that works entirely inside ChatGPT. The experience taught me things that aren't in the docs yet. If you're considering building with the Apps SDK, here's what I wish someone had told me first.
What I built
The Movie Context Provider handles movie search, watchlist management, watch history, user preferences, and AI-powered recommendations, all inside ChatGPT:
Users ask for recommendations, skim results, save titles, and mark things as watched without leaving the thread. Server-side, the app uses ExpressJS and TypeScript, with PostgreSQL for persistence and Valkey to cache calls to TMDB. Widgets are compiled as self-contained HTML bundles with Vite.
Understanding the architecture
The SDK builds on MCP, the Model Context Protocol. MCP is an open standard for connecting LLMs to tools: you describe tools with JSON Schema, handle the logic, and the model decides when to call them based on the conversation. Any MCP-compatible client can use these tools. The Apps SDK extends MCP by adding a widget layer. When your server returns structured content with _meta.openai/outputTemplate metadata, the chat client renders a React component inline. The SDK handles all the plumbing between these pieces.
Whether you build MCP tools first or prototype widgets first is up to you and your workflow. But here's what matters: MCP is an open standard with real traction. Your server defines tools that any MCP-compatible client can call. That means your work isn't locked into ChatGPT. The same server works with Claude Desktop, Cline, or any other MCP client.
I happened to start with a pure MCP server and added widgets later, but that was just my path. The key insight is that this portability isn't theoretical. It's real leverage. You're building on a protocol, not just for a single platform.
Your MCP tools work beyond ChatGPT. That portability is valuable whether you use it day one or later.
The local development workflow
The recommended way to develop is to run your MCP server locally and expose it to ChatGPT through a tunnel like ngrok. Register your app in ChatGPT's developer mode, point it to your ngrok URL, and you can test without deploying every change.
The setup isn't elegant. You're juggling a local server, keeping a tunnel alive, and debugging across multiple interfaces. But it works for fast iteration on server-side logic: change a tool definition, restart, test in ChatGPT.
Once things work locally, deploy to test real performance. The ngrok loop is for building. Production is for validating latency and user experience.
Local dev with ngrok is clunky but gets you iterating fast. Deploy when you need to test real performance.
For widgets, start with a local harness
Widgets are the most compelling part of the SDK. Seeing a React component render inside a conversation feels like the future. But developing them through the full chat loop will break your flow.
I found it much easier to build a local harness before touching ChatGPT. Mount your widget, feed it structuredContent fixtures, stub window.openai.callTool(), and keep iteration in the millisecond rhythm. I built three widgets for the Movie Context Provider: a detailed poster view, a sortable grid, and a preferences editor, and developed all of them locally first.
Without the harness, every widget tweak means going through ChatGPT to see the result: trigger a prompt, wait for the full loop, inspect the rendering. With the harness: edit, save, hot reload, click. The difference is flow versus friction.
The SDK doesn't provide this tooling yet. A local sandbox that renders the same runtime the chat client uses would change the development experience. Until that exists, build your own. It's worth the setup time.
Developing widgets through ChatGPT kills your iteration speed. Build a local harness to keep development fast.
Expect 424 errors and set up defenses
The most time-consuming issue wasn't architectural. It was diagnostic. A 424 Unhandled errors in TaskGroup became a constant companion whenever something broke between the MCP layer and the chat client's renderer.
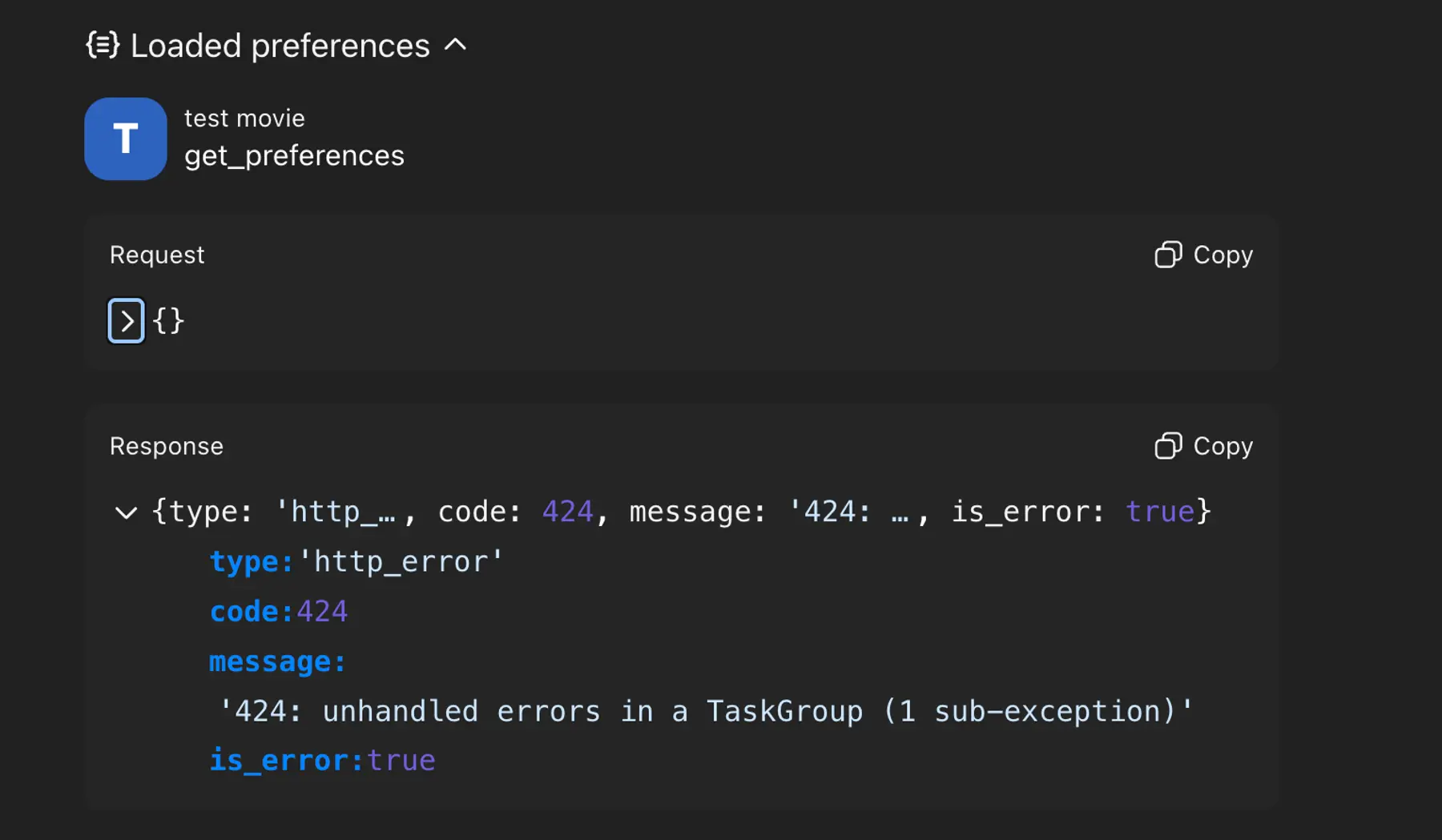
Eventually I learned that 424s almost always trace back to response shape mismatches. If the tool returns something the chat client doesn’t expect — like a malformed structuredContent or missing _meta field — the entire call fails with a generic 424. Once I understood that pattern, debugging got much easier, but getting to that realization took time.
If you hit a 424, start by checking that your tool’s response matches what the client expects. Log the exact payload your tool returns, then compare it against the format described in the Apps SDK docs on structuring return data. Make sure structuredContent is a proper object, _meta is defined, and your output template matches your widget.
What the SDK really needs are errors like this:
Useful errors aren’t a luxury, they’re what make exploration possible. Until those arrive, rely on defensive logging to see what’s really happening.
424 errors won't tell you what's wrong. Log payloads, keep reference fixtures, and version your metadata to debug faster.
Understand the full loop cost
When you're testing through ngrok with ChatGPT, the full chat loop includes several steps:
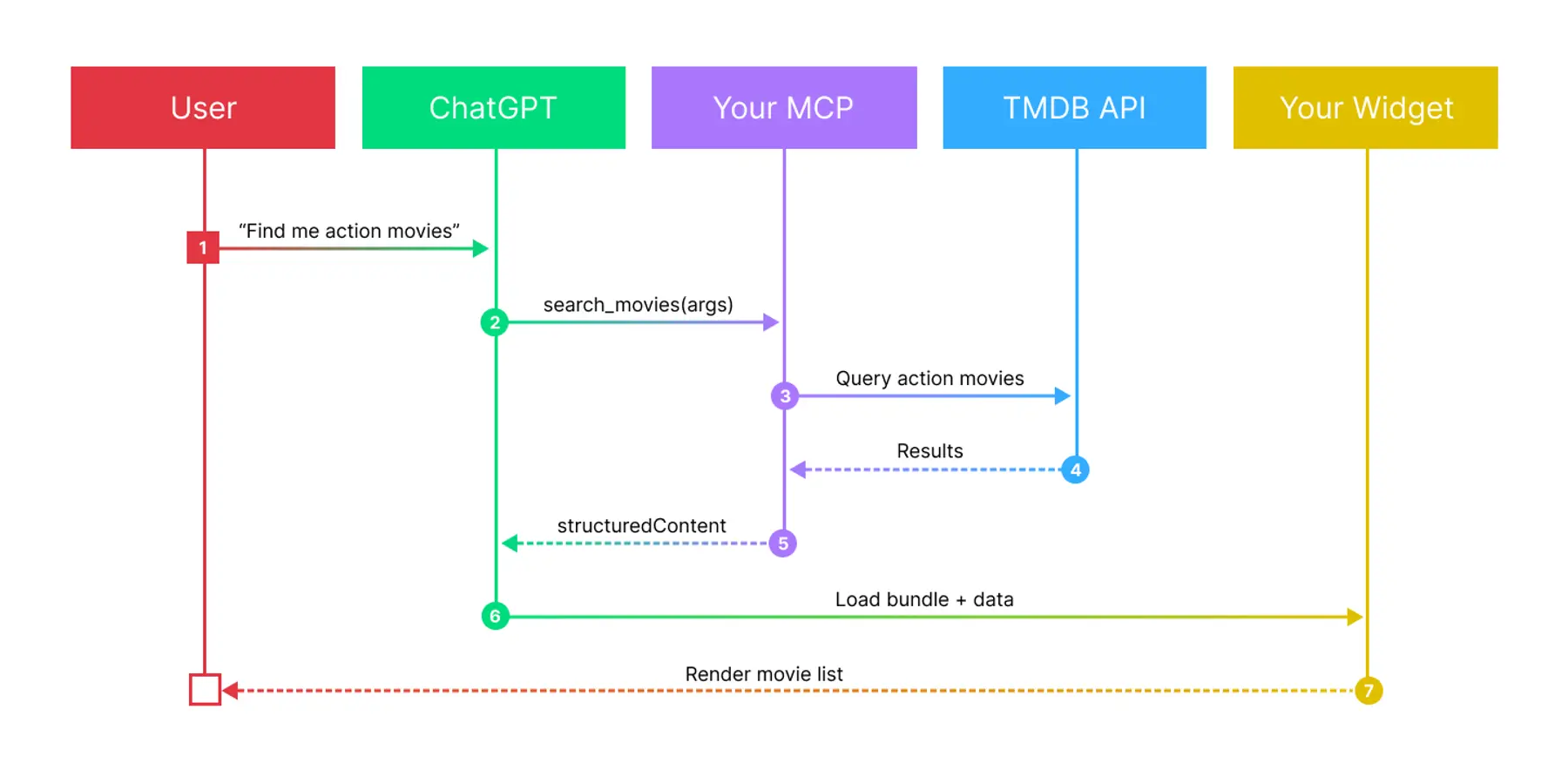
- User enters a prompt
- Model interprets the prompt
- Model decides to call a tool
- MCP server processes the request (may call external APIs like TMDB)
- MCP server returns structured data + widget metadata
- Model interprets the structured data
- ChatGPT renders the widget
The model reasoning time is real in both local and production. The ngrok tunnel adds some artificial overhead. But even in production, the full loop has cost, and without telemetry, you can't tell which hop is the problem. Is it model reasoning? Network latency? Widget rendering? You're crossing rivers blind.
What I really wanted was a client-side switch to temporarily call tools directly, plus basic timestamps for tool.start, tool.finish, and widget.render. Even minimal instrumentation would turn the stacked cost into a clear budget you can act on.
For production apps, implementing full telemetry is important, though streamableHttp makes it trickier since streaming responses don't map cleanly to traditional tracing. For exploration, even a rough breakdown would help you decide what to optimize.
The full chat loop adds up. Without visibility into where time goes, you can't optimize effectively.
Learn from code, not just docs
Documentation exists, but it's thin where you need it most. The primary reference is a demo repo with pizza examples. At the time of writing this post, few end-to-end examples show how the pieces fit together or what good patterns look like beyond the happy path.
The Movie Context Provider repo now adds another reference point, but beyond those, examples are scarce for now. This will change as more developers start building with the SDK. If the docs stay light, these community examples will become the best way to learn, showing how others handle structure, validation, and error recovery in real projects. Until then, expect to experiment and fill in a few gaps yourself.
The docs are thin (for now at least). Learn from code examples, especially from people who've shipped real apps.
Deploy on solid infrastructure
Local development with ngrok gets you building, but it doesn't tell you how the app actually performs. Eventually you need to deploy to see real latency, test under load, and verify the experience feels right to users.
The good news is that Render makes the whole infrastructure part pretty seamless, so you can focus on the end user experience and the SDK itself.
A single Blueprint brought up Postgres, Valkey, the Node MCP server, and static widget assets. HTTPS worked by default. The first deploy applied migrations automatically. Secrets lived in environment groups. Health checks turned misconfigurations into visible red markers. Logs told me which service failed and why. When I needed to roll back, it took one click. The entire production flow runs on Render's free tier, so you can spin up your own version and start building.
The principle that helped me: Pick your foundation carefully. You're working in new territory. Make sure your basecamp is something you can trust completely. That frees you to focus on the SDK itself rather than fighting your infrastructure.
None of this is glamorous, but it’s the difference between exploring and thrashing.
When the SDK is shifting, keep your infrastructure solid. You need at least one part of the stack you can trust.
The path forward
The Apps SDK is an interesting exploration of how richer experiences might live inside a chat interface. Whether that idea takes off or fades out is hard to tell, but it’s worth experimenting with. Building something real is still the best way to understand what this new pattern can do. The rough edges are there, but they're the kind you expect from a new tool in a new space.
The Movie Context Provider demonstrates these patterns in practice: users discover movies, manage lists, and get recommendations without leaving the thread.
The repo is structured as a starting point. If you're exploring the Apps SDK and want reliable infrastructure that just works, fork it and deploy to Render. You'll have a working MCP server with widgets, database persistence, and multi-provider LLM support running in minutes, all on free services. Customize the tools, modify the widgets, or use it as a reference for your own project.
Pioneer tools get better when people try them and report back. If you build something with the Apps SDK, share what you learn. The more scouts map the terrain, the faster the paths become paved roads.