This guest post is kindly contributed by Felt, the web platform for creating and collaborating on maps. Render is proud to help Felt serve mapmakers across the…well…map.
At Felt, we are truly obsessed with speed — we code, we measure, and if things aren’t fast enough, we code them again. This ability to iterate quickly is the secret sauce behind most of our innovations and ability to respond to customer feedback.
The secret ingredient? Our rapid deployment strategy. We consistently deploy more than 10 times, and it's not uncommon to have a 15-deployment day. We don’t stop on Fridays, and people often deploy on a weekend if they want to get a fix (or a feature) out the door before Mondays. In effect, it feels like we are working directly in production at all times. This feeling is built into our culture, and architected in our tooling.
In this post, I am going to talk about how we’ve been able to sustain such a fast speed of iteration with our deployment strategy. I’ll go over a couple of our key principles, such as Day 1 Deploys and PR Reviews and for each principle, we’ll discuss the technology and process decisions we’ve made that made it possible to turn the idea into reality.
Render preview environments
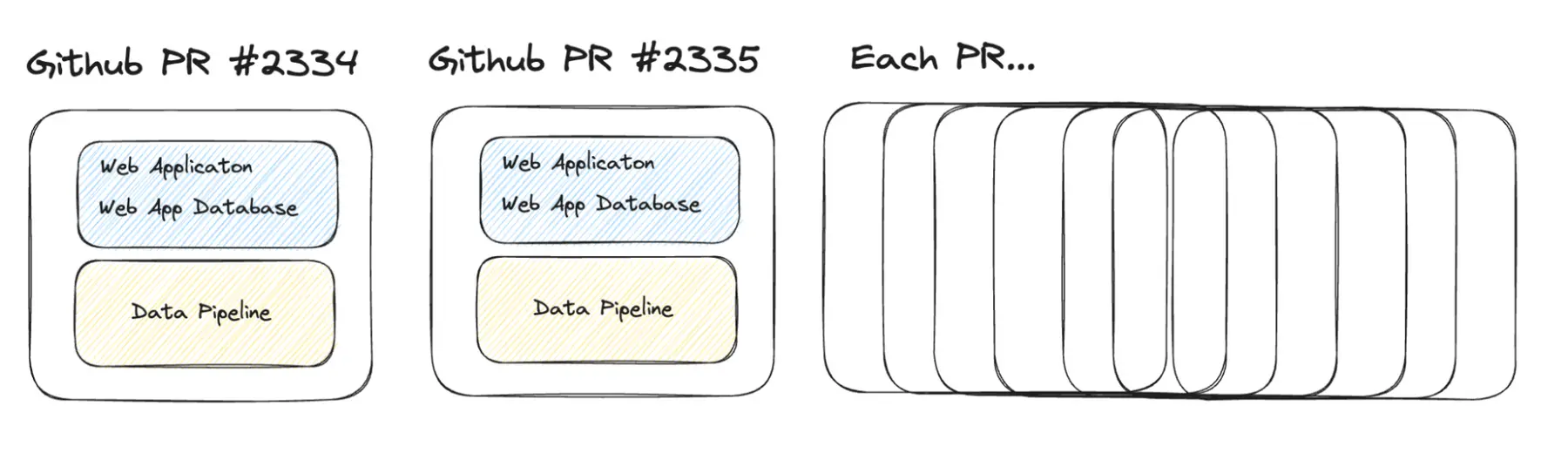
Every pull request is a standalone Felt infrastructure. Instead of fighting over a single staging environment, we make every single change, no matter how small, to become a full-fledged Felt service. Every single pull request gets their isolated environment with its own database, frontend, and backend. This allows a unique way of product testing and development — instead of arguing the benefits of a certain UI interaction compared to another, we’ll build both of them and test them side by side.
Most of this is enabled by using Render’s preview environments via Blueprints (Render's infrastructure-as-code mechanism). We use a declarative format to describe our application servers and our database, and create clones of it for each PR (and Production).
[Editor's note: Check out an example blueprint]
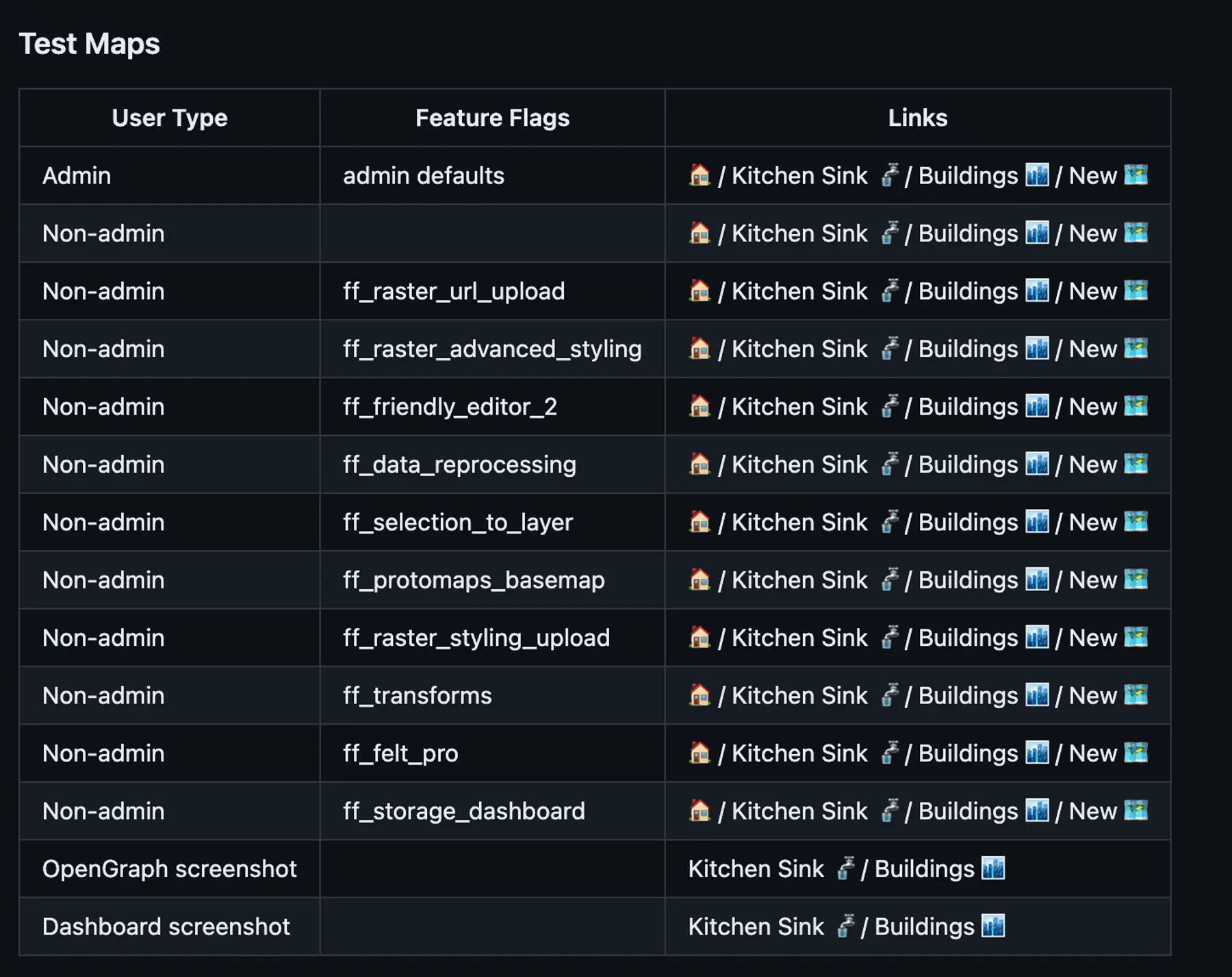
We have extended these environments quite a bit and added a ton of goodies to make our product and engineering teams happier. For example, each Pull Request environment gets seeded with several types of different data that resembles the kinds of user uploads we see. In order to test the app as different types of users, we also create various types of accounts. And to top it all off, we create one-off links for each type of user and map combination and paste them as links to the Github PR page so that we can login with a single “magic link”.
One key thing is that this machinery, like any other, requires constant maintenance. For example, whenever we introduce a new feature, we need to update the corresponding seed data. We also keep a watchful eye on speed — since review applications are an almost exact replica of the entire Felt infrastructure, any slowness we introduce to our deployment procedure gets amplified by the number of review apps we have.
Day 1 deploys
We make starting up Felt as easy as possible. Whenever a new engineer starts, we want them to be able to deploy a small change on their first day. It allows the new hire (or contractor) to feel connected to the product and instills them with our ethos of fast iteration.
On the technology side, Day 1 Deploys means that the application has to be easy to get started on. We’ve really paid attention to our README and made it as foolproof as possible. So far, all our new hires have been able to get the app up and running in less than 25 minutes or so, and most of that is really waiting on compilations of various tools.
On the process side, we hold the hiring managers accountable for this goal — they need to have quick wins ready to go before someone starts, and be ready on Day 1 to hold the new hire’s hand, if needed, to get their code up and running.
Human in the loop automation
Our customers’ data security is critical. Automation increases safety by removing possible human errors. We also know no amount of tooling can (yet?) replace all human judgment. We tread the balance between automation and human judgment by requiring every change that’s deployed to production be tested in production — both automatically and manually.
Take a single pull request being merged to main. Since every merge to main results in a deployment and we often merge faster than a deploy, we use Github Merge Queues. This allows our engineers to be unblocked during merges— instead of hounding the Github PR page to wait until they can merge, they can hit “Merge when Ready” as soon as they are confident with their changes. Github automatically runs the cornucopia of tests we have (all the way from unit tests to end-to-end tests with a Playwright, more than a dozen tests running in parallel), and if they all pass, puts them into the merge queue.
When a change is deployed in production, we then notify the author of the Pull Request in Slack that their change is deployed and ask them to verify the changes work as intended and nothing bad has happened. This doesn’t have to be a arduous process — all we ask is a simple ✅ on the Slack message.
A lot of the technology involved here may not sound exciting — but make no mistake: they are all mission-critical. These various scripts and tooling that check the status of deployments, hold state about whose code is in what state may not feel like production code to many others, but we treat them as such.
One nice thing with this human-in-the-loop process is that it has a built-in back pressure and adapts to individual working styles. Since engineers know they’ll need to test their changes in production, they refrain from making a lot of small changes and sit on Slack all day. However, since no one wants to deploy one big honking change for a major feature and potentially break everything, it also encourages dividing things into manageable, individually testable chunks. And of course, different engineers have different thresholds, and that is totally fine by us.
Other minor technologies and processes
Feature Flags — We use them when we want to control the rollout. This allows us to test some of the more complicated features using production data. But it also helps with marketing — we can enroll some of our more brave customers earlier than others and help get valuable feedback.
Pull Request Etiquette — We require a test plan by the PR author and an approval message by the reviewers. This minor change made a big difference — it encourages a self-reflection on the status of the code and the product on the author’s part and discourages blind rubber-stamping on the reviewer’s part.
Our continued commitment to speed
All this obsession with speed of delivery is to enable a singular goal: be the best place to make maps on the internet. The faster we can get our ideas in front of our customers, the sooner we learn, and bridge the gap between what our users want and what they have.
Fundamentally, engineering is much more exciting and rewarding when you can deploy quickly – and the technology is now in a place where, with the right team, it's possible. When I started my career almost 15 years ago, I remember having to wait on Staging environments and then end up going to lunch and coming back to see a change being reverted because a QA test had failed. It felt like, one way or another, you were limited to 1 or at least 2 changes per day in production. It’s truly amazing to have a deployment strategy that allows for more than 10 a day.
We won't stop here, however. We will continue to improve and push for even faster deployment. If this is the kind of challenge you are excited by, please drop us a line! Felt is hiring and we’d love to chat. [Editor's note: Render is hiring too!]